Why take backups?
If you’re here, you probably already have decided you need backups; if so, feel free to skim through this section. If you’re new to the idea of backups or want a recap though, please keep reading.
Backups are generally designed to protect the data you care about. This data can be anything you want and are generally things like: family photos, digital art projects, save-game files, tax documents, etc.
There are generally two kinds of risks we’re trying to defend against with backups:
- Physical Risks
- Cyber Risks
Physical risks are things that can be dictated by your physical environment or equipment, and include things like fire, flood, theft, hardware failures, or other cases where your important data may not be available when you need it.
Cyber risks are things that are dictated by digital factors like software or users, and include things like ransomware, wiper viruses, accidental deletion, accidental modification, or other unauthorized or unintended actions which could cause you to lose access to your data or which may threaten your data integrity.
Is sync-to-cloud storage good enough?
If you’re using iCloud backups, OneDrive, DropBox, Google Drive, or other services which allow you to sync your files to the cloud, these services will gladly propagate any changes (good or bad) on your local device to the cloud. This means if you delete or overwrite your tax documents on your local computer, there may be no way to recover the file.
Some of these services may allow versioning features to be enabled, or at least provide a “recycle bin” for deleted items. If you’re set on using a cloud storage provider and automatically syncing files, be prepared to do some testing.
Sync-to-cloud is probably good enough for physical risks (e.g. computer drive is physically destroyed or lost) but it is usually not going to prevent cyber risks like ransomware.
Resilient backup principles
In order to have backups that prevent both physical and cyber risks as defined above, we need to have a few key things:
-
Physical Separation of data
- This is the key factor in mitigating physical risks. Simply put: duplicate the data so that you have two copies of the data, including your original/working copy, then store the two copies in different locations (“physically separate” it). The distance between the copies must be such that if something happens to the primary copy, your backup is not affected. This distance will be determined by your risk appetite, the further the better and for most people storing it in another building is good enough.
- Logical Separation of data
- This is a key factor in mitigating cyber risks, and is a little more complicated than the first point. Logical separation means that your backup copy cannot be overwritten, deleted, or otherwise modified from the primary system.
- Immutability
- Immutability extends the idea of Logical Separation, but is the principle that the backup copy should not be able to be overwritten, deleted, or otherwise modified from any digital system (including the backup system or backup storage system).
- Have a plan C.
- Take a third copy and repeat #1, #2, #3 if possible. This copy should be separated from the second copy such that if the second copy is compromised there is no risk to this third copy and vice-versa. Usually this means using some kind of different storage media.
- Please encrypt your backups
- This has no real impact on your ability to recover, but it is worth mentioning: by duplicating data you are adding attack surface and increasing the likelihood that your data are accidentally exposed or leaked. Don’t let your backups be the breach for your personal files, encrypt your backups and store the key somewhere safe.
Considerations for the above principles:
- If the building (or room) where your primary copies are located burns down, will it matter if your backups are destroyed? If not, it may be sufficient physical separation to store your backups in the same room or building which could reduce the cost or complexity of your solution.
- Would you expect a threat that attacks your backups? If not, and you are primarily concerned about accidentally changing or deleting files, #3 and #4 may be overkill.
- Do you want absolute assurance that you can recover the data? If so, you would want the highest degrees of #1-#4.
How does a backup work?
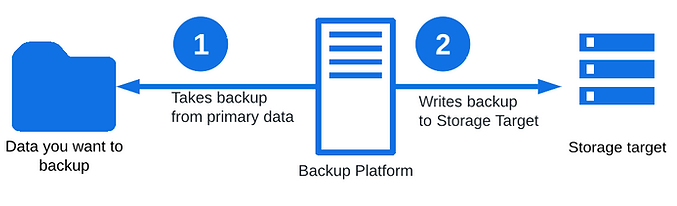
This is oversimplified and generalized, but you will normally have at least three components in your backup architecture. Your primary data (the data you want to back up), your backup platform (mechanism you use to copy the data), and your backup storage (the location where the backup is ultimately stored).
The Backup Platform will take a backup from your primary data, usually do some effort with de-duplication, encryption, and compression, and then write to a storage target (external hard drive, NAS, tape drive, cloud storage, etc).
Backup platforms
I’ve listed two open source solutions I like here. My own opinion is that open source solutions will work for most non-business use-cases which is the focus of Pt 1. (Depending on risk appetite and needs, these may also be entirely viable for business use cases).
Local Files / Single computer
If you just have one system to worry about, or even just a few to manage, I would use Duplicati. It runs locally on the computer and replicates to cloud. If you use this with AWS S3 bucket versioning, you can accomplish #1, #2, #3, and #5 pretty easily. With multiple backup jobs, #4 is also obtainable. Because of the unique block-based storage, it may not be possible to turn on glacier tier storage to reduce costs without some additional engineering.
Duplicati gets points for simplicity, and for most people this should be enough.
https://www.duplicati.com/
https://www.duplicati.com/articles/Storage-Engine/
Bare metal (or VMs) / Multiple computers
If you’ve got a larger environment to worry about, or want to backup your entire system, I would go with Bacula which is enterprise-grade and features a number of additional options (including support for WORM tape…) but is still open source. There will be a lot more tinkering here than with Duplicati. Some features that might be useful for this use case include:
- S3 / Cloud support with local cache to reduce egress charges
- Centralized management for backups of distributed environments
- Scheduling of jobs
- Multi-user support
- Encryption at rest and in transit (including mutual TLS)
- The list goes on
https://www.bacula.org/
Backup Storage Solutions
Cloud S3 Storage
I’m personally a big fan of using cloud storage (especially AWS), and if you size your backups appropriately you can get away with fairly low cost. Amazon S3 is priced at fractions of a dollar per GB for standard tier storage, with options to go much cheaper if you optimize and use glacier for your long-term backups (just make sure you also calculate recovery costs if you use glacier). https://aws.amazon.com/s3/pricing/
Pros:
- Logical separation
- Physical separation (the data is off-site)
- Immutability (if you configure it correctly)
- Granular controls over your data lifecycle and permissions
- Recovery from anywhere to anywhere.
Cons:
- If you have never used cloud services before, or aren’t technical, it might take some time to set up properly and there are risks of misconfiguration.
- Not free
- Slow upload speeds (with most home networks)
Personal Cloud Drive Storage
There’s also personal cloud storage options like DropBox, Google Drive, etc. As mentioned previously, the major downside with these is immutability. To lower the risk you would want to make sure your account security is prioritized to avoid having an attacker delete your backups.
Pros:
- Logical separation (if you do not sync to your computer)
- Physical separation (the data is off-site)
- Recovery from anywhere to anywhere
- Easy to set up
Cons:
- Few options for immutability.
- Not free (can be an expensive subscription in some cases)
- May not work with some options like Bacula
- Slow upload speeds (with most home networks)
Local Storage
If you don’t mind a manual process rotating between two drives, you can achieve some level of immutability with local file systems. (backup to two drives, do not leave them connected, do not connect both at the same time). If you don’t care about immutability and just want some redundancy against drive failure, this is also a good option.
There are other automated options for hardened on-premise storage which don’t really apply to home users, so I won’t mention these.
Pros:
- No ongoing cost (besides replacing dead hardware)
- Faster write speeds than with cloud
- Logical separation is inherent (if you do not leave the drive plugged in).
- Possible to implement immutability if you are careful and do it manually.
- Possible to implement other principles like physical separation (if you don’t mind taking a trip or drive regularly..)
Cons:
- Needs a manual process to implement immutability
- High effort to implement physical separation
- Up-front storage cost
Self-Hosted S3
If you want the benefits of cloud S3 without the slow transfer times and cloud bill, this may be a viable solution. Keep in mind, if the server is on your local network it may also be a target, so use this with caution and be sure to harden the server. You can use something like min.io running on a Raspberry Pi for this.
Pros:
- No ongoing cost (with community license)
- Faster write speeds if local
- Logical separation is inherent
- Immutability is configurable (but remember the host is not necessarily immutable).
- Possible to implement physical separation if you host it off-site (at another house, for example).
Cons:
- Physical separation is harder to achieve
- Much more difficult to set-up and maintain than cloud S3
- Another thing to patch (maintenance)
- Not a set-it and forget-it solution.
- Risks of lateral movement (especially if you keep your SSH or other credentials on the same machine as your primary data).
- Risks of immutability failure
- Risks of mis-configuration
Optimization (for cost savings and speed)
This probably doesn’t matter for smaller environments or for small amounts of data, but for anyone who is interested, here you go:
Traditional Backup Types
Without getting too technical, backups classically fall into three general categories in theory: Incremental, Differential, and Full. There is also Synthetic Full which in practice is more widely used today. This is not by any means exhaustive and there are many other types of backups.
Full backups are an entire copy of all of the data you want to save. These generally are a 1:1 copy of the data and may be compressed to save space.
Differential backups are a copy of the bytes which changed from the last full backup.
Incremental backups are a copy of just the bytes which changed from the last full backup or last incremental backup. The first backup after a full backup is effectively the same as a differential backup.
Synthetic full backups this is a mechanism which merges incremental backups with the most recent full or (synthetic full) backup directly on the storage media. This idea is also sometimes called “Forever Incremental.”
Bandwidth Considerations
Incremental backups are the lowest possible size backup traversing the network.
Differential backups are slightly bigger than incremental backups
Full backups are generally magnitudes larger
Synthetic full backups, if implemented properly, should have the same bandwidth as Incremental backups.
Speed Considerations
Full backups can simply be restored from the full backup data. (fastest restoration time)
Differential backups can be restored with the desired differential backup data, and the full backup data. (slower restoration time)
In order to recover from an incremental backup, you would need all of the previous incremental backups, and the last full backup. (slowest restoration time)
Synthetic full backups should not have any major speed difference from full backups during recovery
Considerations for Backing-up Already Encrypted Files
Most modern backup solutions will have de-duplication and watch for intra-file changes to save on space. If you’re backing up already encrypted files, your incremental backups will probably be larger. This is because encryption is high-entropy, meaning the bytes in a file will have large differences if they are decrypted, modified, and re-encrypted. If you have a low volume of encrypted files to back up and those files do not change very often, this will have a lower impact on your overall incremental backup size.
Scoping your Backups
This is obvious, but if you backup less files, you will use less storage and bandwidth. Consider which files you actually need for your use case. You could, for example, only target irreplaceable files, and leave re-downloadable items alone. This will be more work if you need to restore from scratch, but it may be worth it in the long run if you consider the likelihood you will need to restore.
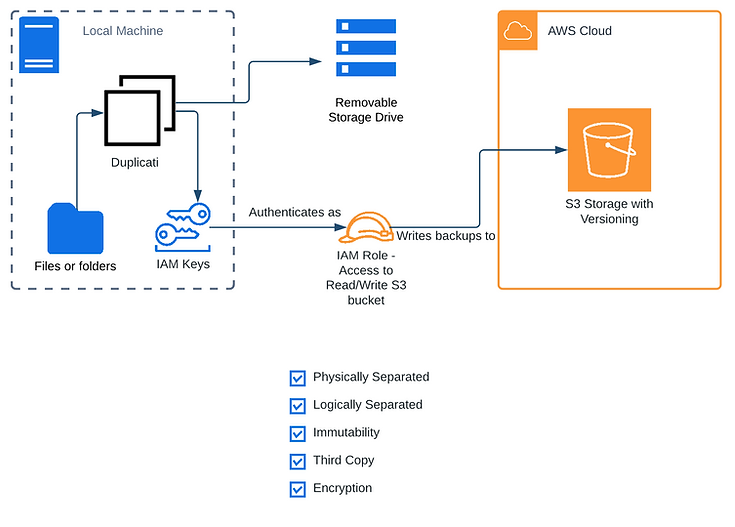
Example Architecture
Here is the simplest example I could think of which checks all of the boxes (principles mentioned). Keep in mind, the “removable storage drive” should be physically disconnected, and connected only for the backup window to preserve the manual immutability. This drive can be kept on-site (even right next to your computer) since off-site backups are handled by the cloud. This example also assumes the S3 bucket is configured with compliance mode object lock to prevent deletion of versions.
This is using Duplicati to AWS S3 and a manual backup to a removable storage drive.